Difference: DESStorageImplement (2 vs. 3)
Revision 32010-12-15 - MichaelOSullivan
| Line: 1 to 1 | ||||||||
|---|---|---|---|---|---|---|---|---|
Implementing a Storage Area Network Prototype | ||||||||
| Line: 466 to 466 | ||||||||
| Both Distributed Replicated Block Device (DRBD) and Red Hat Cluster Suite (RHCS) use a single IP address to identify systems that are part of the distributed replicated block device (DRBD) or cluster (RHCS). In order to make the mirrored block device and the cluster for core-edge storage system reliable, we want to make sure they do not "break" if the link (or NIC) that DRBD or RHCS use fail. To do this we create a new load-shared "link" with a new IP address using Linux Advanced Routing and Traffic Control (LARTC). | ||||||||
| Changed: | ||||||||
| < < | h2 Using LARTC to create a load-shared IP address | |||||||
| > > | Using LARTC to create a load-shared IP address | |||||||
| On all the machines we want to create this single (load shared) IP address. To do this: | ||||||||
| Changed: | ||||||||
| < < | {code} | |||||||
| > > | ||||||||
| modprobe sch_teql tc qdisc add dev eth0 root teql0 tc qdisc add dev eth1 root teql0 ip link set dev teql0 | ||||||||
| Changed: | ||||||||
| < < | {code} | |||||||
| > > | ||||||||
| Changed: | ||||||||
| < < | In our network we have already set the IP addresses as shown in Figure 1, so only the new IP address needs to be set. On Storage 1 we do this: {code} | |||||||
| > > | In our network we have already set the IP addresses as shown below, so only the new IP address needs to be set. On Storage 1 we do this: | |||||||
| ip addr add dev teql0 192.168.10.1/24 | ||||||||
| Changed: | ||||||||
| < < | {code} {image:worksite:/ndsg_cluster_drbd.jpg|ndsg_cluster_drbd.jpg} | |||||||
| > > | ||||||||
| Changed: | ||||||||
| < < | Figure 1 Architecture for DRBD/Multipath Storage Network | |||||||
| > > | 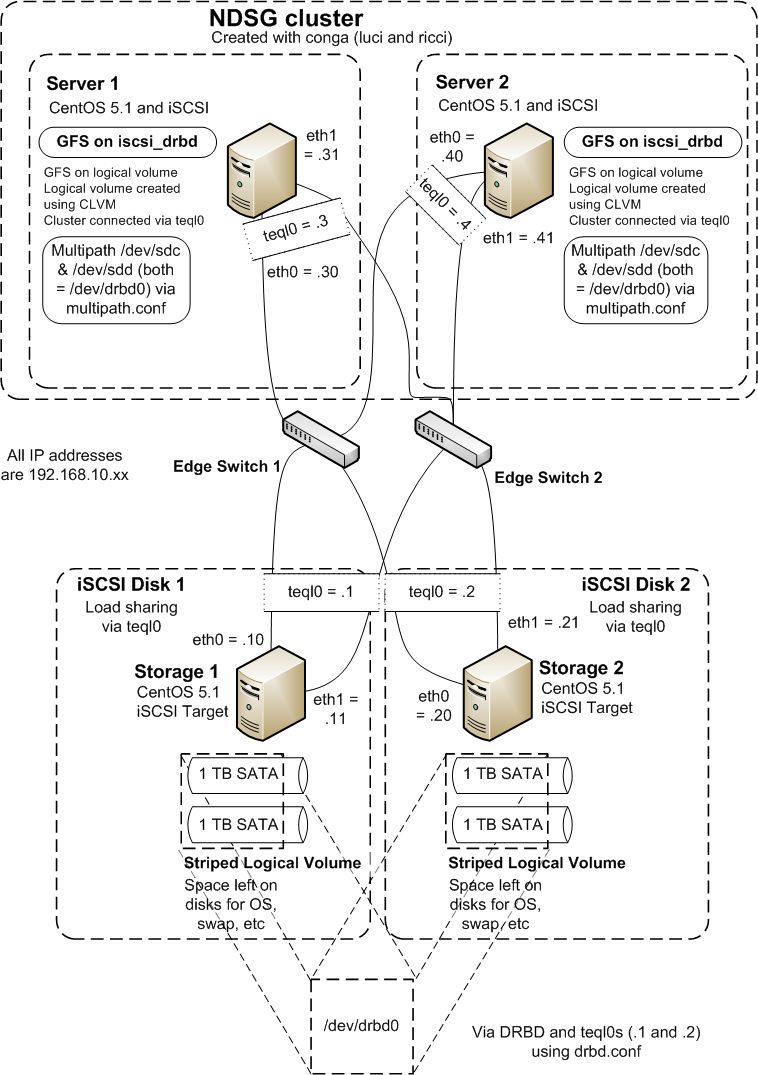 | |||||||
| Changed: | ||||||||
| < < | h2 Using DRBD to mirror the disk | |||||||
| > > | Using DRBD to mirror the disk | |||||||
| Changed: | ||||||||
| < < | First, ensure that DRBD is installed on both storage servers (I used yum in CentOS). Then create /etc/drbd.conf: {code} | |||||||
| > > | First, ensure that DRBD is installed on both storage servers (I used yum in CentOS). Then create /etc/drbd.conf: | |||||||
| common { protocol C; } | ||||||||
| Line: 504 to 502 | ||||||||
| address 192.168.10.2:7799; } } | ||||||||
| Changed: | ||||||||
| < < | {code} | |||||||
| > > | ||||||||
| You may have to "zero" enough space on your device: | ||||||||
| Changed: | ||||||||
| < < | {code} | |||||||
| > > | ||||||||
| dd if=/dev/zero bs=1M count=128 of=/dev/VolGroup00/iscsidisk1; sync | ||||||||
| Changed: | ||||||||
| < < | {code} | |||||||
| > > | ||||||||
| This creates space for the 128MB meta data disk. | ||||||||
| Changed: | ||||||||
| < < | Now create the drbd device on the server. {code} drbdadm create-md ~~resource~~ drbdadm attach ~~resource~~ drbdadm connect ~~resource~~ cat /proc/drbd {code} | |||||||
| > > | Now create the drbd device on the server.drbdadm create-md _resource_drbdadm attach _resource_drbdadm connect _resource_>br>
cat /proc/drbd | |||||||
| Changed: | ||||||||
| < < | See https://www.drbd.org/docs/install/ | |||||||
| > > | See https://www.drbd.org/docs/install/ for more details. | |||||||
| Repeat this process on the other server. | ||||||||
| Changed: | ||||||||
| < < | On ~~one~~ of the storage servers synchronize the data (I am assuming both servers are currently empty): {code} | |||||||
| > > | On one of the storage servers synchronize the data (I am assuming both servers are currently empty): | |||||||
| drbdadm -- --overwrite-data-of-peer primary ~~resource~~ | ||||||||
| Changed: | ||||||||
| < < | {code} | |||||||
| > > | ||||||||
| Now enable a Primary/Primary configuration by adding: | ||||||||
| Changed: | ||||||||
| < < | {code} | |||||||
| > > | ||||||||
| resource ~~resource~~ net { allow-two-primaries; | ||||||||
| Line: 540 to 536 | ||||||||
| } ... } | ||||||||
| Changed: | ||||||||
| < < | {code} to /etc/drbd.conf and using the following commands: {code} | |||||||
| > > |
to /etc/drbd.conf and using the following commands: | |||||||
| drbdadm adjust ~~resource~~ drbdadm primary ~~resource~~ | ||||||||
| Changed: | ||||||||
| < < | {code}
For any problems please consult https://www.drbd.org/ | |||||||
| > > | For any problems please consult https://www.drbd.org/. | |||||||
| Changed: | ||||||||
| < < | h2 Use iSCSI to present the DRBD device | |||||||
| > > | Use iSCSI to present the DRBD device | |||||||
| Changed: | ||||||||
| < < | Now use iSCSI as specified in [Building the Alternative (Core-Edge) SAN | Core-Edge SAN Implementation] with two VERY IMPORTANT differences. This time you will be pointing to a single iSCSI target using two different IP addresses. We will also use a serial number to emulate drbd0 being the same disk. Create a single ietd.conf file as before, add ~~ScsiId=DRBD0~~ to the end of the Lun line in ietd.conf: {code} | |||||||
| > > | Now use iSCSI as specified above with two VERY IMPORTANT differences. This time you will be pointing to a single iSCSI target using two different IP addresses. We will also use a serial number to emulate drbd0 being the same disk. Create a single ietd.conf file as before, add ScsiId=DRBD0 to the end of the Lun line in ietd.conf: | |||||||
| Lun 0 Path=/dev/drbd0,Type=fileio,ScsiId=DRBD0 | ||||||||
| Changed: | ||||||||
| < < | {code} and finally copy this file to the other storage server. This should "fool" the iSCSI initiators into thinking /dev/drbd0 is a single device (which for all intents and purposes it is!). | |||||||
| > > |
and finally copy this file to the other storage server. This should "fool" the iSCSI initiators into thinking /dev/drbd0 is a single device (which for all intents and purposes it is!). | |||||||
| Changed: | ||||||||
| < < | h2 Use Multipath to specify a single device | |||||||
| > > | Use Multipath to specify a single device | |||||||
| Use | ||||||||
| Changed: | ||||||||
| < < | {code} | |||||||
| > > | ||||||||
| scsi_id -g -u -s /block/sdc scsi_id -g -u -s /block/sdd | ||||||||
| Changed: | ||||||||
| < < | {code} | |||||||
| > > | ||||||||
| to make sure your iSCSI target is showing up as the same device on each connection (via the two TEQL devices, i.e., 4 NICs). | ||||||||
| Changed: | ||||||||
| < < | Now edit multipath.conf so that these scsi device (sdc and sdd) are seen as the same device with multiple paths: {code} | |||||||
| > > | Now edit multipath.conf so that these scsi device (sdc and sdd) are seen as the same device with multiple paths: | |||||||
| # This is a basic configuration file with some examples, for device mapper # multipath. # For a complete list of the default configuration values, see | ||||||||
| Line: 693 to 688 | ||||||||
| # path_grouping_policy multibus # } #} | ||||||||
| Changed: | ||||||||
| < < | {code} h2 Set up GFS on RHCS | |||||||
| > > | ||||||||
| Changed: | ||||||||
| < < | Now we have single mirrored disk presented to both Server 1 and Server 2 so we can create a cluster and GFS as in [Building the Alternative (Core-Edge) SAN | Core-Edge SAN Implementation]. However, one important difference is the presence of the TEQL devices. Use these IP addresses in the /etc/hosts file an d the cluster will not break if a single NIC goes down. Otherwise, use ricci and luci or cman, rgmanager and clvmd as before to set up a cluster with a GFS system. | |||||||
| > > | Set up GFS on RHCS | |||||||
| Changed: | ||||||||
| < < | h3 Problem! | |||||||
| > > | Now we have single mirrored disk presented to both Server 1 and Server 2 so we can create a cluster and GFS as above. However, one important difference is the presence of the TEQL devices. Use these IP addresses in the /etc/hosts file an d the cluster will not break if a single NIC goes down. Otherwise, use ricci and luci or cman, rgmanager and clvmd as before to set up a cluster with a GFS system. | |||||||
| Added: | ||||||||
| > > | Problem! | |||||||
| It appears that a TEQL device does not work well with RHCS, causing a split-brain problem in a 2-node cluster. We will replace the TEQL devices with bonded NICs since speed is not an issue in the controller cluster. | ||||||||
| Changed: | ||||||||
| < < | First, replace /etc/sysconfig/network-scripts/ifcfg-eth0 and /etc/sysconfig/network-scripts/ifcfg-eth1 with the following file: {code} | |||||||
| > > | First, replace /etc/sysconfig/network-scripts/ifcfg-eth0 and /etc/sysconfig/network-scripts/ifcfg-eth1 with the following file: | |||||||
| DEVICE=ethX # <- use eth0 or eth 1 as appropriate USERCTL=no ONBOOT=yes MASTER=bond0 SLAVE=yes BOOTPROTO=none | ||||||||
| Changed: | ||||||||
| < < | {code} Then, create a new file /etc/sysconfig/network-scripts/ifcfg-bond0: {code} | |||||||
| > > |
Then, create a new file /etc/sysconfig/network-scripts/ifcfg-bond0: | |||||||
| DEVICE=bond0 IPADDR=192.168.10.4 NETMASK=255.255.255.0 | ||||||||
| Line: 722 to 716 | ||||||||
| ONBOOT=yes BOOTPROTO=none USERCTL=no | ||||||||
| Changed: | ||||||||
| < < | {code} Next, add the following lines to /etc/modprobe.conf: {code} | |||||||
| > > |
Next, add the following lines to /etc/modprobe.conf: | |||||||
| alias bond0 bonding options bond0 mode=0 # <-mode=0 means balance-rr or balanced round robin routing | ||||||||
| Changed: | ||||||||
| < < | {code} | |||||||
| > > | ||||||||
| Finally, restart the networking | ||||||||
| Changed: | ||||||||
| < < | {code} | |||||||
| > > | ||||||||
| service network restart | ||||||||
| Changed: | ||||||||
| < < | {code} | |||||||
| > > | ||||||||
| alternatively | ||||||||
| Changed: | ||||||||
| < < | {code} | |||||||
| > > | ||||||||
| /etc/rc.d/init.d/network restart | ||||||||
| Changed: | ||||||||
| < < | {code} | |||||||
| > > | ||||||||
| Now, there should be a bonded dual-NIC interface for running RHCS. | ||||||||
| Changed: | ||||||||
| < < | h2 More Architecture Problems It appears that having the entire architecture on the same subnet means that only one switch can be "seen" at a time. Splitting it up using VLANs is not a solution as VLANs and TEQL devices don't seem to mix properly. By changing all eth0 to be on the 192.168.20.xx subnet and all eth1 to be on 192.168.30.xx subnet, we can see both switches (192.168.20.5 and 192.168.30.5 respectively). The TEQL devices can be 192.168.50.xx combining the 192.168.20.xx and 192.168.30.xx interfaces. The 192.168.50.xx subnet is then used for both iSCSI and DRBD. Finally, the bonding can happen on VLAN 4 (so add eth0.4 and eth1.4 to the two cluster servers) to provide redundancy for RHCS (see /etc/hosts). | |||||||
| > > | More Architecture Problems | |||||||
| Added: | ||||||||
| > > | It appears that having the entire architecture on the same subnet means that only one switch can be "seen" at a time. Splitting it up using VLANs is not a solution as VLANs and TEQL devices don't seem to mix properly. By changing all eth0 to be on the 192.168.20.xx subnet and all eth1 to be on 192.168.30.xx subnet, we can see both switches (192.168.20.5 and 192.168.30.5 respectively). The TEQL devices can be 192.168.50.xx combining the 192.168.20.xx and 192.168.30.xx interfaces. The 192.168.50.xx subnet is then used for both iSCSI and DRBD. Finally, the bonding can happen on VLAN 4 (so add eth0.4 and eth1.4 to the two cluster servers) to provide redundancy for RHCS (see /etc/hosts). | |||||||
| Changed: | ||||||||
| < < | {image:worksite:/san_architecture_drbd.jpg|san_architecture_drbd.jpg} Figure 2 Final architecture | |||||||
| > > | The final architecture is shown below:
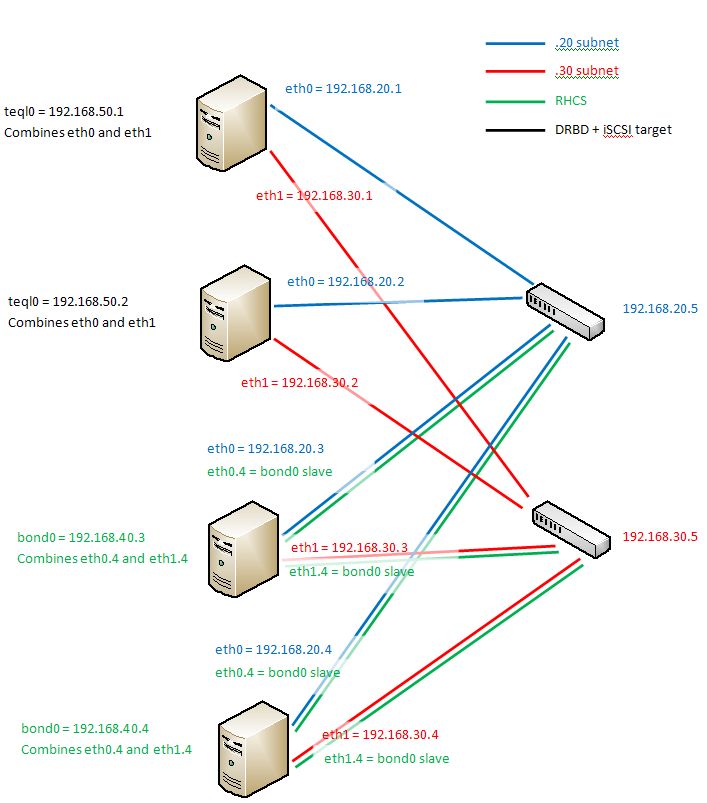 | |||||||
| -- MichaelOSullivan - 15 Dec 2010 | ||||||||
| Line: 753 to 746 | ||||||||
| ||||||||
| Added: | ||||||||
| > > |
| |||||||
View topic | History: r7 < r6 < r5 < r4 | More topic actions...
Ideas, requests, problems regarding TWiki? Send feedback